
Regex Applications in Data Science
In our previous blog on Regex, we went through the detailed structure of a regular expression. Further, we looked at several components required to build a regular expression using the re module in python and did some examples. In this blog, we will focus on the industrial applications of regex by implementing it to some tedious tasks that wouldn’t be possible without regular expressions. Let’s look at some standard applications of regular expressions in data science:
- Web-Scrapping & Data Collection
- Text Preprocessing (NLP)
- Pattern Detection for IDs, E-mails, Names
- Date-time manipulations
We will discuss each of the above applications in the simplest way possible with implementation in python. We will be using multiple datasets in the analysis. Let’s start with our first application:
Web-Scrapping & Data Collection
Data Collection is a significant part of any project since it consumes a lot of time and effort. Nevertheless, collecting textual data over the web is far more accessible thanks to libraries like beautiful soup, Scrapy, and Selenium. The collected data often requires cleaning, and cleaning tasks are tedious. With the help of regular expressions, we can clean web data efficiently and promptly.
Let’s take a look at the URL data:
with open('html.txt', 'r', encoding='utf-8-sig') as html:
raw_url_data = html.read()
print(raw_url_data)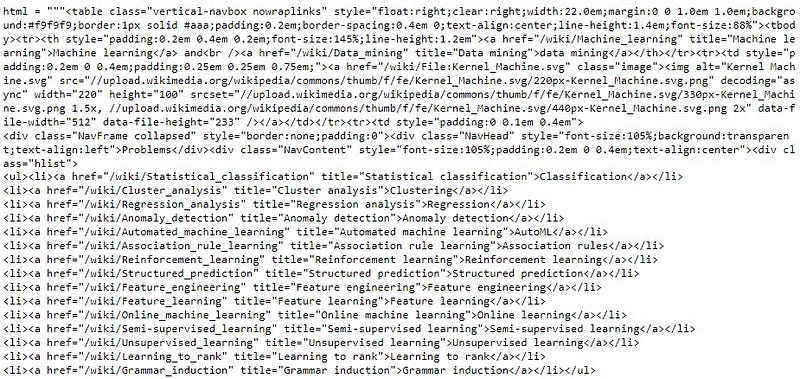
The real-world unstructured data looks something like this. Our job is to extract the links carefully without losing any crucial information. Tackling this task manually might not seem challenging since there are only a few lines but imagine if we have millions of rows with the same kind of complex text. Thanks to regex, we can extract the desired links with a few lines of code even if we have millions of rows present in the data. Let’s see how we can extract the links.
import re
import time
start_time = time.time()
clean_urls = re.findall(r'href=[\'"]?([^\'" >]+)', raw_url_data)
print('--- Executed in %s seconds ---' % (time.time() - start_time))
print('\n'.join(clean_urls))
'''
# Output
--- Executed in 0.0 seconds ---
/wiki/Machine_learning
/wiki/Data_mining
/wiki/File:Kernel_Machine.svg
/wiki/Statistical_classification
/wiki/Cluster_analysis
/wiki/Regression_analysis
/wiki/Anomaly_detection
/wiki/Automated_machine_learning
/wiki/Association_rule_learning
/wiki/Reinforcement_learning
/wiki/Structured_prediction
/wiki/Feature_engineering
/wiki/Feature_learning
/wiki/Online_machine_learning
/wiki/Semi-supervised_learning
/wiki/Unsupervised_learning
/wiki/Learning_to_rank
/wiki/Grammar_induction
/wiki/Supervised_learning
/wiki/Statistical_classification
/wiki/Regression_analysis
/wiki/Decision_tree_learning
/wiki/Ensemble_learning
/wiki/Bootstrap_aggregating
/wiki/Boosting_(machine_learning)
/wiki/Random_forest
/wiki/K-nearest_neighbors_algorithm
/wiki/Linear_regression
/wiki/Naive_Bayes_classifier
/wiki/Artificial_neural_network
/wiki/Logistic_regression
/wiki/Perceptron
/wiki/Relevance_vector_machine
/wiki/Support-vector_machine
'''We executed the extraction in less than a millisecond with just a one-liner regular expression. Further, if there’s a case where we might have to extract even more specific links, we can even design a regex for that.
Libraries like beautiful soup now support link parsing, which is even more innovative and convenient. Now let’s look at our second application.
Text Preprocessing
Text data is collected from a variety of sources, namely the feedback forms, web-scrapped text, text extracted from images using OCRs, etc. Such diverse data comes with high inconsistencies that should be removed before diving into any language modeling task. Language modeling tasks include sentiment analysis, language translation, text generation, name entity recognition, etc. Each of the mentioned tasks requires clean text data for modeling.
Let’s take a look at some inconsistent text:
import numpy as np
from sklearn.datasets import fetch_20newsgroups
Text, label = fetch_20newsgroups(return_X_y=True, categories=[
'alt.atheism',
'sci.med',
'comp.windows.x',
'misc.forsale',
'rec.autos',],)
Text = np.array(Text).reshape(-1, 1)
print(Text)
'''
# Output
array([['From: bmaraldo@watserv1.uwaterloo.ca
(Commander Brett Maraldo)\nSubject: Ampex 456 2"
Recording Tape For Sale\nOrganization: University
of Waterloo\nDistribution: na\nLines: 19\n\n\n\tI have
5 full reels of Ampex 456 2" recording tape.
This tape was\nused once at 15 ips and carefully stored.
All reel include an Ampex tape\nband. The tape has not
been bulk erased to my knowledge. The history of\nthe
tape in know and available upon request. JMAR in
Toronto sells new\n2" 456 for $260+tax (Canadian)
I would like $100CDN/reel which will include\npostage.
\n\nBrett Maraldo\n- Plexus Productions\n\nps.
The reels are 2500\' long; standard thickness.\n\n\n-- \n -------- Unit 36 Research ---------\n\t "Alien Technology Today"\n \t \t bmaraldo@watserv1.UWaterloo.ca\n \t {uunet!clyde!utai}!watserv1!bmaraldo\n'],
['From: keith@cco.caltech.edu (Keith Allan Schneider)
\nSubject: Re: <Political Atheists?\nOrganization: California
Institute of Technology, Pasadena\nLines:
50\nNNTP-Posting-Host: punisher.caltech.edu\n\nbobbe@vice.ICO.TEK.COM
(Robert Beauchaine) writes:\n\n>>I think that about 70%
(or so) people approve of the\n>>death penalty, even
realizing all of its shortcomings.
Doesn\'t this make\n>>it reasonable?
Or are *you* the sole judge of reasonability?\n>Aside
from revenge, what merits do you find in capital
punishment?\n\nAre we talking about me, or the majority
of the people that support it?\nAnyway, I think that
"revenge" or "fairness" is why most people are in\nfavor
of the punishment. If a murderer is going to be punished,
people\nthat think that he should "get what he deserves."
Most people wouldn\'t\nthink it would be fair for the
murderer to live, while his victim died.\n\n>Revenge?
Petty and pathetic.\n\nPerhaps you think that it is petty
and pathetic, but your views are in the\nminority.\n\n>We
have a local televised hot topic talk show that very
recently\n>did a segment on capital punishment. Each
and every advocate of\n>the use of this portion of our
system of "jurisprudence" cited the\n>main reason for
supporting it: "That bastard deserved it". True\n>human
compassion, forgiveness, and sympathy.\n\nWhere are we
required to have compassion, forgiveness, and sympathy?
If\nsomeone wrongs me, I will take great lengths to make
sure that his advantage\nis removed, or a similar situation
is forced upon him. If someone kills\nanother, then we can
apply the golden rule and kill this person in turn.\nIs not
our entire moral system based on such a concept?\n\nOr, are
you stating that human life is sacred, somehow, and that it
should\nnever be violated? This would sound like some sort
of religious view.\n \n>>I mean, how reasonable is
imprisonment, really, when you think about it?\n>>Sure,
the person could be released if found innocent, but you
still\n>>can\'t undo the imiprisonment that was served.
Perhaps we shouldn\'t\n>>imprision people if we could watch
them closely instead. The cost would\n>>probably be similar,
especially if we just implanted some sort of\n>>electronic
device.\n>Would you rather be alive in prison or dead in the
chair? \n\nOnce a criminal has committed a murder, his
desires are irrelevant.\n\nAnd, you still have not answered
my question. If you are concerned about\nthe death penalty
due to the possibility of the execution of an innocent,
\nthen why isn\'t this same concern shared with imprisonment.
Shouldn\'t we,\nby your logic, administer as minimum as
punishment as possible, to avoid\nviolating the liberty
or happiness of an innocent person?\n\nkeith\n']'''The data in hand is reasonably inconsistent and can be removed using regular expressions. Let’s make a list of operations for the creation of the text preprocessing pipeline:
- Replacing new-line characters with space
- Removing email addresses
- Removing symbols
- Removing digits
Let’s apply them one by one to the above data!
import re
for sentence in Text:
new_line_removed = str(sentence).replace(r'\n', ' ')
email_removed = re.sub(r'[A-Za-z0-9]*@[A-Za-z]*\.?[A-Za-z0-9]*', ' ', new_line_removed)
symbols_removed = re.sub('[^A-Za-z0-9]+', ' ', email_removed)
clean_data = re.sub(r"(^|\W)\d+", ' ', symbols_removed)
print(clean_data)
# Output
'''
From uwaterloo ca Commander Brett Maraldo Subject Ampex
Recording Tape For Sale Organization University of Waterloo
Distribution na Lines I have full reels of Ampex
recording tape This tape was used once at ips and carefully
stored All reel include an Ampex tape band The tape has not
been bulk erased to my knowledge The history of the tape in
know and available upon request JMAR in Toronto sells new
for tax Canadian I would like CDN reel which will include
postage Brett Maraldo Plexus Productions ps The reels are
long standard thickness Unit Research Alien Technology
Today UWaterloo ca uunet clyde utai watserv1 bmaraldo
From edu Keith Allan Schneider Subject Re Political
Atheists Organization California Institute of Technology
Pasadena Lines NNTP Posting Host punisher caltech edu TEK
COM Robert Beauchaine writes I think that about or so
people approve of the death penalty even realizing all
of its shortcomings Doesn t this make it reasonable Or
are you the sole judge of reasonability Aside from revenge
what merits do you find in capital punishment Are we
talking about me or the majority of the people that support
it Anyway I think that revenge or fairness is why most
people are in favor of the punishment If a murderer is
going to be punished people that think that he should
get what he deserves Most people wouldn t think it would
be fair for the murderer to live while his victim died
Revenge Petty and pathetic Perhaps you think that it is
petty and pathetic but your views are in the minority We
have a local televised hot topic talk show that very
recently did a segment on capital punishment Each and
every advocate of the use of this portion of our system
of jurisprudence cited the main reason for supporting it
That bastard deserved it True human compassion forgiveness
and sympathy Where are we required to have compassion
forgiveness and sympathy If someone wrongs me I will take
great lengths to make sure that his advantage is removed or
a similar situation is forced upon him If someone kills
another then we can apply the golden rule and kill this
person in turn Is not our entire moral system based on such
a concept Or are you stating that human life is sacred
somehow and that it should never be violated This would
sound like some sort of religious view I mean how reasonable
is imprisonment really when you think about it Sure the
person could be released if found innocent but you still
can t undo the imiprisonment that was served Perhaps we
shouldn t imprision people if we could watch them closely
instead The cost would probably be similar especially if we
just implanted some sort of electronic device Would you rather
be alive in prison or dead in the chair Once a criminal has committed a
murder his desires are irrelevant And you still have not
answered my question If you are concerned about the death
penalty due to the possibility of the execution of an
innocent then why isn t this same concern shared with
imprisonment Shouldn t we by your logic administer as
minimum as punishment as possible to avoid violating the
liberty or happiness of an innocent person keith
'''Our text data has been transformed into this. Cleaning this corpus took four lines of regex statements and less than a millisecond to execute. There are other superior libraries like NLTK and spaCy, capable of performing similar cleaning operations over text data. We will discuss them in a separate session.
Extraction of IDs, E-mails, Names
Targeted Extraction of strings is the most critical application of regex. The sales and marketing team usually requires E-mail IDs, Names from large pieces of text for their marketing campaigns. Extracting the E-mail IDs by manual efforts is a tiresome task. This is precisely the use case where Regex shines.
Extracting E-mail Addresses
Let’s extract E-mail IDs from the last piece of text:
import re
match = re.findall(r'[\w._%+-]+@[\w.-]+\.[a-zA-Z]{1,4}', str(Text))
match
'''
# Output
['bmaraldo@watserv1.uwaterloo.ca',
'bmaraldo@watserv1.UWaterloo.ca',
'keith@cco.caltech.edu',
'nbobbe@vice.ICO.TEK.COM',
'koreth@spud.Hyperion.COM',
'kaminski@netcom.com',
'1993Apr19.205615.1013@unlv.edu',
'todamhyp@charles.unlv.edu',
'nkaminski@netcom.com',
'bmoss@grinch.sim.es.com',
'dyer@spdcc.com',
'1993Apr17.195202.28921@freenet.carleton.ca',
'ab961@Freenet.carleton.ca',
'ndyer@ursa-major.spdcc.com']
'''We have successfully extracted the list of emails with a single line of a regular expression. Let’s break down this pattern to understand how it is working.
[\w._%+-]: Matches any alpha-numeric string (Includes upper and lower case letters) including symbols like dot (‘.’), percentage (‘%’), plus (‘+’), minus (‘-’), and underscore(‘_’). With this, we covered the local part of the e-mail address.
+@: The local name is followed by an (at-the-rate) symbol (‘@’). The plus (‘+’) symbol ensures multiple occurrences.
[\w.-]: This matches the domain name. Which again can be any alpha-numeric string, including the dot (‘.’) and hyphen (‘-’) symbols
.[a-zA-Z]{1,4}: This matches multiple alpha-numeric strings post dot, and this alpha-numeric string structure can repeat at max four times and a minimum of one time. So, we mentioned {1,4}.
And, that’s it! We can extract any discernable pattern.
Extracting Indian Passport Number
Let’s try extracting the Indian passport number from the text using Regex.
import re
raw_text = ["My passport number is T0282033 and for my daugter, it is A2302428"]
match = re.findall(r'[A-Z]{1}[0-9]{7}', str(raw_text))
print(match)
# Output
['T0282033', 'A2302428']The pattern for finding the passport number in the text is relatively more straightforward.
[A-Z]{1}: Ensures the first character to be an upper case alphabet ranging between A-Z inclusive.
[0–9]{7}: Ensures later seven characters to be numbers ranging between 0–9 inclusive.
Our findings can be validated further using the passport number validation algorithm.
Extracting Aadhaar Number
The Aadhaar Number is an Indian national identity number provided to Indian citizens as their identity card. It has a 12-digit number that is unique to each country resident. Let’s try extracting the 12-digit Aadhaar number using regex.
Note: Aadhaar Number can’t be validated without using the Verhoeff Algorithm. For the exact validation of Aadhaar number, please visit this link.
import re
raw_text = ['My aadhaar number is 2230 2428 3421']
adhar_number_patn = '[0-9]{4}\s[0-9]{4}\s[0-9]{4}'
match = re.search(adhar_number_patn, str(raw_text))
print(match.group())
# Output
# [2230 2428 3421]The pattern logic is again simple! Let’s check the explanation:
[0–9]{4}: Ensures the first four digits are within the range 0 to 9.
\s: Matches any whitespace character.
The above combination is repeated two more times to obtain the search pattern. However, we need to validate the received Aadhaar number with the Verhoeff Algorithm to get the authentic result.
Date Time Manipulations using Regex
Date Time is the most common parameter while working with the temporal datasets and such columns carry significant information for data modeling. However, the Date and Time format varies across datasets, and it becomes difficult to work with them. Using regex, we can mold any date-time structure as per the requirements.
Suppose we want to extract year and month from the timestamp!
import re
date = "2022-04-30 02:10:18"
match = re.findall(r'[0-9]{4}-[0-9]{2}', str(date))
print(match)
# Output
# ['2022-04']We can also extract them separately!
import re
date = "2022-04-30 02:10:18"
match = re.findall(r'([0-9]{4})-([0-9]{2})', str(date))
print(match)
# Output
[('2022', '04')]Suppose we have a date like this: 17th October 2022, and we want to extract the day, month, and year separately. Let’s make slight changes in the pattern:
import re
date = "17th October 2022"
match = re.findall(r'(\d{2})\w+\s(\w+)\s(\d{4})', str(date))
print(match)
# Output
[('17', 'October', '2022')]Conclusion
We witnessed some excellent applications of regular expressions in the data science domain. Regular expressions have minimized the data cleansing efforts by a far portion. Regular expressions have been extended to human-computer interactions, and we might see some more significant applications in the near future. Hopefully, by the end of this session, you may realize that writing a regular expression is not a cumbersome task. With little practice, anyone can master regular expressions. If you have used regular expressions before? Please share your experience by commenting below!